8. 뮤텍스와 세마포어의 차이점은 무엇인가요?
- 뮤텍스(Mutex) : 락에 대한 키를 두고 해당 키를 소유한 프로세스만이 공유 메모리에 접근이 가능하도록 구현하는 방식
세마포어(Semaphore) : 공유 메모리 접근 권한에 대한 허용 범위를 지정해 해당 범위 내의 개수만큼 접근하는 프로세스의 수를 제한하도록 구현하는 방식
- 위 두 방식의 차이점
- 세마포어는 뮤텍스가 될 수 있지만, 뮤텍스는 세마포어가 될 수 없다.
- 세머포어는 소유하지 못하지만 뮤텍스는 소유할 수 있다.
- 세마포어는 여러 개의 동기화 대상을 가지며 뮤텍스는 오직 하나의 동기화 대상만을 가진다.
이진(바이너리) 세마포어와 뮤텍스의 차이에 대해 설명해 주세요.
| 바이너리 세마포어 | 뮤텍스 |
|---|---|
| 신호 전달 메커니즘 기반으로 동작 | 잠금 메커니즘 기반으로 동작 |
| 현재 스레드보다 우선순위가 높은 스레드가 바이너리 세마포어를 해제하고 잠글 수 있음 | 뮤텍스를 획득한 스레드는 크리티컬 섹션에서 나갈 때만 뮤텍스 해제 가능 |
| 값은 wait() , signal() 에 따라 변경 | 값이 locked, unlocked 으로 수정 |
| 여러 개의 스레드가 동시에 이진 세마포어를 획득 가능 | 한 번에 하나의 스레드만 뮤텍스를 획득 가능 |
| 소유권이 없다 | 뮤텍스를 소유한 스레드만 잠금을 해제 가능하므로 소유권이 있음 |
| 다른 스레드/프로세스가 잠금 해제가 가능하기 때문에 뮤텍스보다 빠르다. | 획득한 스레드만 잠금 해제가 가능하므로 바이너리 세마포어보다 느리다. |
9. Deadlock 에 대해 설명해 주세요.
- 데드락이란 두개의 프로세스가 다른 데이터를 점유하고 있는 상태에서, 서로가 점유하고 있는 데이터를 요구하면서 무한히 대기하는 상태를 의미합니다.
Deadlock 이 동작하기 위한 4가지 조건에 대해 설명해 주세요.
- 데드락이 발생하기 위해선 아래 조건을 모두 충족해야 합니다.
- 상호 배제 : 프로세스는 한번에 하나의 자원만 점유가 가능하다.
- 점유와 대기 : 이미 하나의 자원은 점유하고 있고 다른 자원을 대기하고 있는 프로세스가 있어야 한다.
- 비선점 : 이미 점유된 자원을 뺏어올 수 없다.
- 순환 대기 : 프로세스 집합에서 프로세스들이 자원에 대해서 순환 구조로 대기하고 있어야 한다.
그렇다면 3가지만 충족하면 왜 Deadlock 이 발생하지 않을까요?
- 상호 배제 X : 한번에 두개 이상의 프로세스 점유가 가능하므로 대기 필요가 없어집니다.
- 점유와 대기 X : 점유된 자원에 대한 접근 시 대기가 아니라 종료가 됩니다.
- 비선점 X : 다른 자원을 뺏어올 수 있습니다.
순환 대기 X : 두개 이상의 프로세스가 서로를 바라보면서 대기해야 하는 상황이 아니라 각자 다른 프로세스가 점유한 자원을 대기한다면 무한 대기가 발생하지 않는다.
- 게다가 순한 대기 조건의 경우 점유와 대기, 비선점 조건에 의존하는 조건입니다. 즉, 두 조건이 우선적으로 만족해야만 순환 대기 조건 성립이 가능합니다.
어떤 방식으로 예방할 수 있을까요?
- 위와 같은 조건이 충족하는 상황에서 데드락 해결 방법은 아래와 같습니다.
- 예방 : 데드락이 발생할 수 있는 조건을 미리 허용하지 않는 방식
- 상호 배제 방지 : 모든 자원 공유 허용(현실적으로는 불가능)
- 점유와 대기 방지 : 자원을 점유하지 않은 상태에서만 점유가 가능
- 비선점 방지 : 필요한 자원을 미리 모두 선점
- 순환 대기 방지 : 자원 요청을 순서에 따라 한방향으로 가능
- 회피 : 데드락이 발생할 수 있는 상황을 피하는 방식으로 자원을 할당
- 은행원 알고리즘 : 자원을 제공할 때, 모든 프로세스가 필요한 자원을 점유하고 데드락이 발생하지 않을 지 확인 후 점유를 허용하는 방식
- 탐지 및 복구 : 데드락 발생 여부를 감지하고 문제가 해결될 때까지 복구하는 방식
- 자원 할당 그래프로 자원과 프로세스간의 관계를 표현하고 탐지 알고리즘을 통해 순환 여부를 체크해 데드락 여부를 확인합니다.
- 만약 데드락이 식별되었다면 모든 프로세스를 종료하거나 하나의 프로세스가 데드락이 해결될 때까지 자원을 뺐어 다른 프로세스에 할당합니다.
- 예방 : 데드락이 발생할 수 있는 조건을 미리 허용하지 않는 방식
왜 현대 OS는 Deadlock을 처리하지 않을까요?
- 상대적으로 자주 발생하는 문제가 아닙니다. 이러한 문제를 위해 지속적으로 확인 및 예방하는 로직을 실행시키는 것은 오히려 더 큰 오버헤드를 발생시킵니다.
- 또한 현대 OS의 복잡성(멀티 프로세스, 병렬 처리 등)에선 완전한 데드락 예방은 힘들다고 볼 수 있습니다.
Wait Free와 Lock Free를 비교해 주세요.
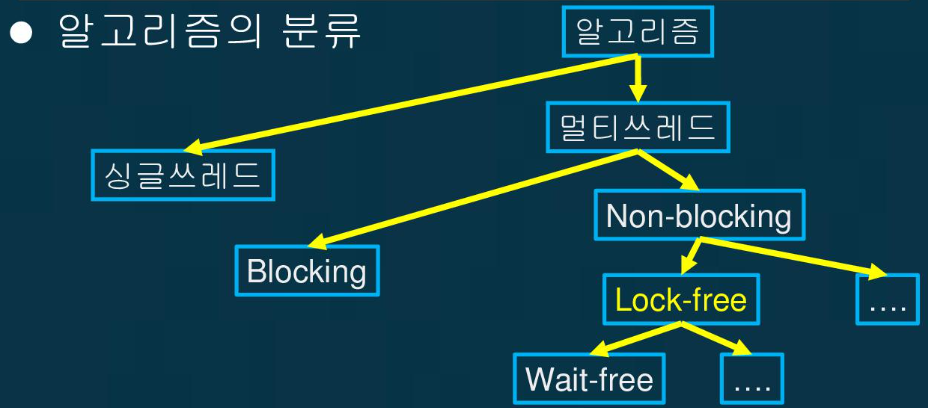
- Lock Free
- 특정 작업을 동시에 여러 쓰레드가 호출했을 때 적어도 하나는 완료해서 반환하는 알고리즘입니다.
- Non-Blocking(비동기) 알고리즘에 속합니다.
- 다른 쓰레드가 동작할 때 다른 쓰레드도 대기 없이 자원을 사용할 수 있어야 하기 때문에 CAS가 반드시 필요합니다.
- 결국, 대기에 대한 소요가 없을 수 있다면 Lock Free 알고리즘이라고 볼 수 있습니다.
- Wait Free
- Lock Free 알고리즘에서 한단계 더 발전한 형태라고 볼 수 있고 Lock Free 알고리즘 범주에 속합니다.
- 여러 쓰레드가 하나의 작업을 동시에 호출했을 때 지연 없이 모든 쓰레드가 동시에 작업을 완료할 수 있는 알고리즘을 의미합니다.
- Michael-Scott Queue가 Wait Free 알고리즘에 속합니다.
10. 프로그램이 컴파일 되어, 실행되는 과정을 간략하게 설명해 주세요.

- 전처리기 : C/C++ 에서
#define,#include와 같이 코드 내에서 특정 지시문을 미리 수행시켜주는 역할을 합니다. 컴파일 전 처리해야 하는 작업을 우선 처리해주는 것입니다. - 컴파일러 : 프로그래밍 언어를 어셈블리어로 변경해주는 역할을 합니다.
- 어셈블러 : 어셈블리어를 컴퓨터가 이해할 수 있는 이진법 형태로 변경해주는 역할을 합니다.
- 링커 : 참조해야 할 함수나 라이브러리를 묶어 하나의 실행 파일로 만들어주는 역할을 합니다.
- 로더 : 실행 파일에 정보돌을 메모리에 적재시켜서 CPU가 실행할 수 있는 준비를 시켜줍니다.
링커와, 로더의 차이에 대해 설명해 주세요.
- 링커 : 실행 가능한 파일을 생성하는 작업을 담당합니다.
- 로더 : 생성된 파일을 목적에 맞게 메모리에 적재하는 작업을 담당합니다.
컴파일 언어와 인터프리터 언어의 차이에 대해 설명해 주세요.
- 컴파일 언어
- 전체 파일을 컴파일 과정을 거쳐 하나의 바이트 코드로 구성된 실행 파일을 만든 다음, 해당 실행 파일을 가지고 실행시키는 방식으로 동작합니다.
- 그러다 보니 빌드 과정에서 필요하고 수정 시 새롭게 빌드해 실행 파일을 생성해야 하는 불편함이 있습니다.
- 하지만 실행 과정에선 이미 빌드된 파일을 가지고 즉시 기계어로 실행이 가능해 처리 속도는 빠르다고 할 수 있습니다.
- 인터프리터 언어
- 빌드 과정 없이 실행과 동시에 코드를 한줄씩 읽어서 기계어로 변환시킨 다음 동작합니다.
- 컴파일 언어와 반대로 빌드 과정이 없어 수정 후 추가적인 과정이 필요하지 않습니다.
- 하지만 실행 속도는 상대적으로 느리다는 단점이 있습니다.
JIT에 대해 설명해 주세요.
- Java에서는 JVM에서 컴파일 과정을 통해 자바 코드를 바이트 코드로 변환하고 메모리에 적재해서 실행 및 동작합니다.
- 그리고 필요에 따라 바이트 코드를 기계어로 변환해 자바 기반의 어플리케이션이 동작하는데 이 과정을 담당하는 녀석이 JIT 컴파일러 입니다.
- 즉, 정적 컴파일러는 자바 코드를 바이트 코드로 변환하고 그 상태에서 필요에 따라 JIT 컴파일러가 동적 컴파일러로써 기계어로 변환해 실행시킵니다.
- JIT 컴파일러는 성능 최적화를 위해 특정 기준에 부합하는 코드의 경우는 기계어인 채로 캐싱해 사용할 수 있습니다.
본인이 사용하는 언어는, 어떤식으로 컴파일 및 실행되는지 설명해 주세요.
- JAVA를 기준으로 설명하자면
- 정적 컴파일러가 자바 코드를 바이트 코드로 구성된 파일로 변환합니다.
- 바이트 코드로 변환된 파일들을 JVM은 읽어 메모리 영역에 적재합니다. 즉 로딩시킵니다.
- 실행 상태에선 JIT 컴파일러가 필요한 바이트코드를 기계어로 변환해 처리합니다.
- 그 과정에서 반복적으로 사용되는 코드는 기계어인 상태로 캐싱해 관리합니다.
Python 같은 언어는 CPython, Jython, PyPy등의 다양한 구현체가 있습니다. 각각은 어떤 차이가 있을까요? 또한, 실행되는 과정 또한 다를까요?
- 구현체 라는 것은 Python으로 이뤄진 프로그램이 실제로 실행될 수 있게끔 만든 프로그램을 의미합니다.
- 이 구현체는 여러 언어 환경에서 제공되고 있습니다.
- CPython : 표준 구현체로 C언어로 구성이 되어 있으면 인터프리터 방식으로 동작합니다.
- Jython : Java 기반으로 만들어진 구현체로 JVM 위에서 동작합니다. 즉 컴파일 방식으로 동작합니다.
- PyPy : Python 기반으로 만들어진 구현체로 JIT 컴파일러 방식으로 구현되어 기존 인터프리터 방식보다 빠른 성능을 보여줍니다.(캐싱 능력)
11. IPC가 무엇이고, 어떤 종류가 있는지 설명해 주세요.
- IPC(Inner Process Communication)란 CPU의 개수가 늘어나고 여러 프로세스를 동시가 실행하는 환경에서 프로세스 간의 데이터 공유를 위한 목적으로 사용되는 기법입니다.
- 이는 프로세스간의 상태를 확인하기 위함의 목적이 있다고 볼 수 있습니다.
- 프로세스간의 협력을 해야 하는 상황은 아래와 같습니다.
- 정보 공유 (Information sharing) : 여러 사용자가 동일한 정보를 필요로 할 수 있다.
- 계산 가속화 (Computation speedup) : 특정 작업(task)를 빠르게 실행하기 위해, 해당 작업을 부분 작업(서브 태스크)으로 나눠서 병렬로 실행하게 할 수 있다.
- 모듈성 (Modularity) : 특정한 시스템 기능을 별도의 프로세스(스레드)로 구분하여 모듈식 형태로 시스템을 구성할 수 있다.
- 편의성 (Convenience) : 여러 사용자들이 동시에 많은 작업을 수행할 수 있다.
- 구현 종류는 아래와 같습니다.
- 공유 메모리
- 세마포어
- 메세지 큐
공유 메모리 범위에 세마포어가 포함된다? 차이는 어떤게 있을까?
Shared Memory가 무엇이며, 사용할 때 유의해야 할 점에 대해 설명해 주세요.
- 그 중 Shared Memory 기법은 커널 영역에 별도의 메모리 공간을 할당하고 키를 부여해 키를 통해 여러 프로세스가 하나의 데이터에 접근하고 공유가 되도록 하는 방식을 의미합니다.
- Shared Memory는 커널에서 관리하며 별도의 메모리 공간을 가집니다. 그리고 각 프로세스들은 이 메모리를 바라보고 있을 별도의 메모리 공간을 할당해야 합니다.
- 이는 프로세스 내에서 텍스트 영역과 데이터 영역 사이에 저장됩니다.
- 또한 Shared Memory에 저장되는 데이터 또한 static한 성격을 가집니다. 이는 다른 프로세스에서 접근이 용이하고 관리가 편리해야 하는데 그러기 위해선 정적으로 메모리를 할당받고 변하지 않는 두 영역 사이가 적합하기 때문입니다.
메시지 큐는 단방향이라고 할 수 있나요?
- 큐 자체는 단방향으로 동작하는 것이 일반적입니다.
- 하지만 큐를 두개로 구성하고 두 프로세스가 양방향으로 통신할 수 있도록 구성할 수 있습니다.
양방향 통신이 가능한 큐가 있을 수 있다? 양방향 구현체가 있다?
12. Thread Safe 하다는 것은 어떤 의미인가요?
- 멀티 스레드 환경에서 일반적으로 어떤 함수나 변수, 혹은 객체가 여러 스레드로부터 동시에 접근이 이루어져도 프로그램의 실행에 문제가 없는 것을 의미합니다.
- 즉, 다른 스레드의 작업으로 인해 의도와 다른 결과가 나오지 않도록 이를 보장하는 것을 의미합니다.
Thread Safe 를 보장하기 위해 어떤 방법을 사용할 수 있나요?
- Mutual Exclusion (상호 배제)
- 공유 자원 하나에 하나의 스레드만 접근해 처리할 수 있도록 통제하는 방식입니다.
- 주로 뮤텍스 또는 세마포어 방식으로 구현합니다.
- 가장 많이 사용하는 방식이지만 락으로 인해 대기가 길어질수록 성능이 저하됩니다.
- Atomic Operation (원자 연산)
- 공유 자원에 접근하는 방식이나 내부 연산을 원자적으로 구현하는 것을 의미합니다.
- 즉, 각각의 스레드가 처리하는 연산 자체를 원자적으로 구성해 서로 영향을 주지 않도록 하는 것입니다.
- 이를 위해 CAS 개념을 적용해 구현해 볼 수 있습니다.
- Thread-Local Storage (쓰레드 지역 저장소)
- 각 쓰레드만 접근할 수 있는 지역 저장소를 사용하는 방식입니다.
- 공유 자원을 사용할 지 않는 방법이 존재하는 경우 적용할 수 있는 방식입니다.
- Re-Entrancy (재진입성)
- 재진입성(Re-entrancy)은 함수나 코드 조각이 이미 실행 중인 상태에서 다시 호출될 수 있는 능력을 의미합니다.
- 함수가 실행 중일 때 해당 함수가 다시 호출되더라도 이전 실행의 영향을 받지 않고 독립적으로 실행될 수 있는 특성을 가지고 있는 것을 의미합니다.
- 각각의 스레드는 함수 시작 시 초기 상태를 별도로 저장해 구현할 수 있습니다.
Peterson’s Algorithm 이 무엇이며, 한계점에 대해 설명해 주세요.
- flag와 turn이라는 변수를 사용해 공유 자원 접근 권한을 얻은 후에 자원에 접근할 수 있도록 스핀락을 걸어주는 방식입니다.
- flag : 공유 자원에 접근하겠다는 의도를 표현하며 접근을 희망한다면 true로, 처리 후 빠져나왔다면 false로 표현합니다.
- turn : 현재 공유 자원 접근 차례를 표현하며 i번째 프로세스는 turn이 i가 될 때까지 대기하게 됩니다.
- flag가 true고 turn이 본인 차례가 될 때까지 대기를 하게 되며 두 조건에 부합할 경우 공유 자원에 접근할 수 있습니다.
- 상호 배제를 보안하기 위해 구현된 알고리즘입니다. (인터럽트로 인해 락 권한이 꼬여 두개의 쓰레드가 동시에 접근하는 경우를 방지)
Race Condition 이 무엇인가요?
- 공유 자원에 대해 여러 프로세스가 동시에 접근을 시도할 때, 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태를 의미합니다.
- 이름 그대로 여러 프로세스 또는 스레드가 경쟁 상태에 있는 것을 의미합니다.
Thread Safe를 구현하기 위해 반드시 락을 사용해야 할까요? 그렇지 않다면, 어떤 다른 방법이 있을까요?
- 꼭 그렇지 않으며 Mutual Exclusion (상호 배제) 방식을 채택하고자 할 경우에는 락을 통해 Thread Safe한 형태를 구현할 수 있습니다.
- 하지만 원자 연산, 쓰레드 지역 저장소, 재진입성 방식을 채택할 경우에는 락을 사용하지 않더라도 Thread Safe한 구조로 구성할 수 있습니다.
- 그 외에도 Lock Free, Wait Free 알고리즘을 구현할 수 있습니다.
- 이러한 경우는 원자 연산과 동일하게 CAS 기법을 사용해야 합니다.
13. Thread Pool, Monitor, Fork-Join에 대해 설명해 주세요.
- Thread Pool
- 프로세스 동작 간에 필요에 따라 쓰레드 객체를 생성하는 것이 아니라 미리 특정 개수만큼의 쓰레드 객체를 생성해두고 사용 및 반납하기 위한 쓰레드 객체 저장 공간을 의미합니다.
- 객체의 재사용성이 높아지면서 불필요한 객체 생성 소요가 없어지는 장점이 있습니다.
- 하지만 쓰레드 객체 수에 대한 적절한 기준점을 잡지 못하면 부족하거나 남아서 노는 쓰레드 객체가 생겨날 수도 있습니다.
- Monitor(참고자료)
- 쓰레드 간의 동시성을 제어하기 위한 조건과 대기를 걸어주는 역할을 Monitor라고 합니다.
- 즉, 하나의 객체에 여러 쓰레드가 접근하는 것을 제어하고 순서를 정해주는 역할을 합니다.
- JAVA에선 synchronized 키워드를 메소드마다 추가해둠으로써 synchronized 블럭 내에 하나의 쓰레드가 들어갈 수 있도록 상호 배제 역할을 해줍니다.
- 이러한 방식을 고유락이라고 부르며 모니터 락이라고도 합니다.
- 하나의 객체에 우선 접근해 고유락을 잡은 쓰레드가 처리가 끝나고 락을 반환하기 전까지 다른 쓰레드는 대기 상태에 들어가며 반환이 된 이후에 대기 중인 스레드를 깨워 경쟁을 통해 고유락을 소유하도록 합니다.
- Fork-Join
- 하나의 작업을 끝내기 위해 여러 작업 단위로 나눠처리한 다음 결과를 합치는 방식을 의미합니다.
- 분활 정복 과정으로 재귀적인 형태로 동작합니다.
- JAVA에선 별도의 클래스로 Fork-Join 방식 적용 로직을 구현할 수 있습니다. (ForkJoinPool)
뮤텍스와 모니터의 차이?
- 동작 원리 자체는 똑같이 동작하지만 모니터는 특정 조건에 맞지 않으면 대기 큐에서 대기하도록 동작한다.
- 뮤텍스가 조금 더 넓은 범위의 개념. 뮤텍스 안에 모니터가 구체적
Thread Pool을 사용한다고 가정하면, 어떤 기준으로 스레드의 수를 결정할 것인가요?
- 여러가지 계산 법이 있습니다.
- 스레드 풀 적정 크기 = CPU 코어 수 * (1 / CPU 사용 시간)
- 스레드 풀에서 사용중인 스레드 수 = 1초 당 요청 수 * 평균 요청 처리 시간 (리틀의 법칙)
- 하지만 적절한 크기를 선정하기 보단 부족하거나 넘치는 수를 설정하지 않도록 하는 것이 중요합니다.
- 즉, 일정 범위 내에서 크게 자원이 부족하거나 낭비되지 않는 선에서 유지하는 방향을 가지는 것이 합리적이라는 의미입니다.
14. 캐시 메모리 및 메모리 계층성에 대해 설명해 주세요.
- CPU가 자주 사용하게 되는 데이터의 경우 디스크에서 때에 따라 직접 가져오는 것이 아닌 CPU와 가까운 위치에 저장해 더 빠른 속도와 효율성을 가지고 조회할 수 있도록 해주는 메모리 공간을 캐시 메모리라고 할 수 있습니다.
- 캐시는 계층 구조로 구분되어 구성됩니다.
- 가장 상위 계충인 L1 캐시는 용량은 작지만 CPU와 가깝게 있어 가장 빠른 조회 속도를 가져올 수 있습니다.
- 그 다음 L2, L3 캐시의 경우는 점차 CPU와 멀어지면서 조회속도는 느려지지만 용량은 조금 더 크다고 할 수 있습니다.
- 현대에선 L3는 L1, L2에 비해 성능에 직접적인 영향을 주진 않습니다. 그래서 존재하지 않는 경우도 있습니다.
캐시 메모리는 어디에 위치해 있나요?
- L1은 CPU 칩 안에 내장되어 있습니다.
- L2는 CPU 회로판의 별도의 칩으로 존재합니다.
- L3의 경우 CPU가 아니라 메인 보드에 존재합니다.
- 위와 같은 위치상 특징 때문에 속도에서도 차이가 발생합니다.
L1, L2 캐시에 대해 설명해 주세요.
- L1 캐시는 CPU에 내장되어 있으면서 가장 빠른 조회 속도 성능을 내는 캐시입니다.
- 가장 가까운 위치에 있기 때문에 최우선 조회 대상이 됩니다.
- L2 캐시는 CPU 칩에 별도에 저장공간을 가지며 L1에 비해 성능상 조금 느립니다. 하지만 용도와 역할을 비슷합니다.
캐시에 올라오는 데이터는 어떻게 관리되나요?
- 해시 테이블과 비슷한 원리도 동작합니다.
- 주소별로 정해진 캐시 메모리에 위치가 존재하며 이 주소를 기준으로 매핑해 캐시 메모리에서 데이터를 조회합니다.
- 하지만 캐시 메모리는 디스크보다 용량이 작기 때문에 디스크 주소 값을 전부 사용하지 못하고 태그와 인덱스로 분리한 다음, 인덱스만을 키로 활용합니다.
- 그리고 태그는 매핑한 데이터의 정확성을 확안하기 위한 값으로만 사용됩니다.
- 동작을 표현하는 이미지는 다음과 같습니다.
![]()

추가로 캐시 교체 정책에 대해서도 정리 필요
캐시간의 동기화는 어떻게 이루어지나요?
- 캐시 간의? 동기화?
캐시 메모리의 Mapping 방식에 대해 설명해 주세요.
- 직접 매핑 (direct mapping)
- 이 매핑 방식은 메인 메모리를 일정한 크기의 블록으로 나누고 각각의 블록을 캐시의 정해진 위치에 매핑하는 방식입니다.
- 세 가지 매핑 방법 중 가장 간단하며 구현도 가장 쉬운 방식입니다.
- 하지만 적중률이 낮아지며 충돌 이슈가 발생할 수 있다는 단점이 있습니다.
- Full Associative Mapping
- 캐시 메모리의 빈 공간에 마음대로 주소를 저장하는 방식입니다.
- 저장하는 것은 매우 간단하다는 단점이 있습니다.
- 직접 매핑보다 충돌에 대한 이슈가 적어 적중률이 상대적으로 높습니다.
- 원하는 데이터가 있는지 찾기 위해서는 모든 태그를 병렬적으로 검사해야 하기 때문에 복잡하고 비용이 높다는 단점이 있다.
- Set Associative Mapping
- Direct Mapping과 Full Associative Mapping의 장점을 결합한 방식이며 빈 공간에 마음대로 주소를 저장하되, 미리 정해둔 특정 행에만 저장하는 방식입니다.
- Direct에 비해 검색 속도는 느리지만 저장이 빠르고 Full에 비해 저장이 느리지만 검색은 빠르다.
캐시의 지역성에 대해 설명해 주세요.
- 데이터에 대한 접근이 시간적 혹은 공간적으로 가깝게 발생하는 것을 의미합니다.
- 적중률을 극대화해 캐시의 효율성을 챙기기 위한 성질입니다.
- 캐지 지역성은 다음과 같습니다.
- 공간 지역성
- 최근에 사용했던 데이터와 인접한 데이터가 참조될 가능성이 높다.
- 배열의 경우 연속적으로 데이터가 조회, 저장되므로 공간 지역성을 가지고 있다고 볼 수 있습니다.
- 시간 지역성
- 최근에 사용했던 데이터가 재참조될 가능성이 높다.
- 반복문의 경우 같은 데이터가 반복해서 사용되는 경우가 있다면 시간 지역성을 가지고 있다고 볼 수 있습니다.
- 공간 지역성
캐시의 지역성을 기반으로, 이차원 배열을 가로/세로로 탐색했을 때의 성능 차이에 대해 설명해 주세요.
- 배열을 가로로 탐색하는 것이 세로로 탐색하는 것보다 공간 지역성의 기준에선 효율적이라고 볼 수 있습니다.
- 이는 하나의 배열을 연속적으로 탐색하는 식으로 동작하기 때문입니다.
- 그리고 시간 지역성 측면에서도 좋다는 의견이 있다.
- 같은 로우를 계속 탐색하고 다음 로우로 넘어가기 때문에 반복적으로 같은 로우를 탐색한다는 측면에서 시간 지역성이 높다고 할 수도 있습니다.
캐시의 공간 지역성은 어떻게 구현될 수 있을까요? (힌트: 캐시는 어떤 단위로 저장되고 관리될까요?)
- 캐시는 캐시 라인 단위로 저장됩니다.
- 각각의 캐시 라인은 실제 데이터의 일부를 담고 있으며 디스크에 저장된 데이터의 주소 정보와 상태 정보를 포함합니다.
라인 말고 블록 단위도 있다. -> 블록 단위로 데이터를 가져올 때 공간 지역성이 구현되는 부분이 있을 수 있다.
그리고 캐시 교체 정책으로도 공간 지역성을 구현할 수 있다고 할 수 있다.
15.메모리의 연속할당 방식 세 가지를 설명해주세요. (first-fit, best-fit, worst-fit)
- first-fit
- 가장 처음으로 요구하는 메모리에 맞는 공간에 할당하는 방식입니다.
- 알고리즘 상으로 가장 효율적이지만 internal fragmentation(내부 단편화)이 크게 발생할 수 있습니다.
- best-fit
- 남은 공간 중에 가장 internel fragmentation이 적은 메모리 공간에 할당하는 방식입니다.
- 공간 효율적인 측면에선 가장 좋은 알고리즘이지만 가장 적합한 공간이 어디인지 찾아야되는 시간 필요합니다.
- worst-fit
- 가용 공간 중에 가장 큰 공간에 할당하는 방식입니다.
- best-fit과 반대의 접근 방식으로 가장 효율적이기 위해 가장 넓은 빈공간은 만들자는 취지 입니다.
- 하지만 단편화 문제는 일부 완화해주는 경향도 있습니다.
외부 단편화, 내부 단편화 참고 자료
worst-fit 은 언제 사용할 수 있을까요?
- 다른 성능을 비교 분석하기 위해서 사용할 수 있습니다.(사실 거의 쓰이지 않기 때문에…)
성능이 가장 좋은 알고리즘은 무엇일까요?
- 알고리즘 상으로는 first-fit이 가장 효율적이라고 볼 수 있습니다.
- 이는 남은 두 알고리즘은 전체 빈 메모리를 일일이 대조해보고 적합한 공간을 찾아야 하지만, first-fit은 처음 찾은 메모리에 바로 저장되기 때문입니다.
- 하지만 best-fit과는 성능상 큰 차이는 없는 경우도 있다고 합니다.